findings on VLMs
acknowledgements
- Tomáš Daniš for helping me with my understanding of the
AnyMALpaper as well as checking my codebase for errors, this project would not have happened without his help. - vik for
moondream1which inspired me to start working on VLMs andmoondream2, which helped me make an image-caption dataset. finally, thanks for the great test images used in this post.
background
after spending a long time toying around with small projects and shelving them, i decided it was time for me to start working on something bigger. witnessing the advancements of VLMs using smaller models such as Phi and more efficient training methods such as AnyMAL i thought it would be interesting to train one using only local resources, meaning a 3090.
my plan was to work on this for about a month and release a good model, sadly i can only release a small alpha model, but hopefully my learnings will help or teach you interesting things.
AnyMAL
AnyMAL is a paper from meta which introduced an efficient way of adding multimodality to LLMs, using LLaMA-2-70B-Chat as its base model. the paper is however light in details, so here’s how it works:
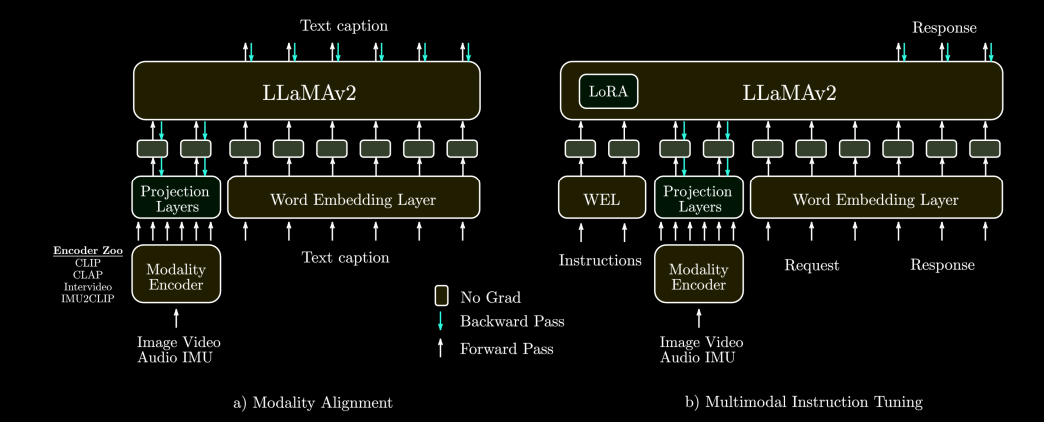
modality alignment
- a pretrained model is chosen for each modality, such as
CLIPfor images,CLAPfor audio, etc. - a projection module is created and will be trained to convert the modality model’s features into the word embedding space (i.e the model creates
LLaMAembeddings from the modality’s embeddings). - the text model is then fed these new embeddings, and has to generate the caption associated with the modality’s sample.
- the projection module is trained using cross-entropy loss between the generated caption and the real caption.
- the text model and modality model’s weights are frozen during this process.
multimodal instruction tuning
- after having trained a good projection module, we want to make sure that our text model is good at answering questions on our modalities.
- using a dataset of modality question answering, a LoRA is trained for our text model, and we continue to train our projection module, using cross-entropy loss between the generated response to the instruction and the correct response.
- the modality model and the text model’s weights are frozen during this process.
projection module architecture
- for most modalities, the projection module is either a single linear layer or a few layers MLP.
- interestingly, for vision modalities a perceiver resampler was used, which was introduced in the
flamingopaper. - the projection modules have a fixed number of tokens for modalities, for example 64 for images.
thoughts on the paper
it was a very intriguing read since the fact it uses a chat model as its base meant that it would be a lot less compute intensive to get a good instruct-tuned model for multimodalities. i, however, wasn’t sure about certain parts:
- during modality alignment, i felt that training the model to generate a caption after the modality embeddings would cause the projection module to train certain embeddings to have a meaning similar to “caption:”, and therefore adding image/caption delimiters would be necessary.
- i feared that using models that were overfit on instruction tuning or used DPO would make modality alignment difficult due to it not using a chat template.
- the model simply mentions that the projection module uses the modality model’s “input signal”, which is rather vague. to me, this meant one of two things, the final embedding of models like
CLIP(a single embedding of size 768), or the embeddings of the ViT (576 embeddings of size 768). considering the vision modality uses 64 tokens, it had to be the ViT patches, however, i was interested in seeing the results i would get using the final embedding. - i had no knowledge of perceiver resamplers and felt like it would take me too much time to focus on this, considering other modalities and
LLaVAuse MLPs for modality alignment.
with all these thoughts in mind, i decided to focus on image modalities using clip-vit-large-patch14-336, using linear layers instead of a perceiver resampler, however to stay close to AnyMAL, i did not add image/caption delimiters at first, and chose NousResearch/Nous-Hermes-2-Mistral-7B-DPO as my text model. my goal was to train using the largest model i possibly could, and focus only on the modality alignment, hoping it would be enough to get good results as i would not have the resources to train a LoRA as well.
first architecture
for my first attempt, i used a very simple architecture, a two-layer MLP with the first layer taking the final CLIP embedding and outputting one text-model embedding, and the second layer outputting 8 text-model embeddings, and the activation function being ReLU.
for the dataset, i used Flickr30k and filtered to have an image caption similarity of 0.3, which ended up with about 10k images.
what i expected to be a very bad model turned out to be extremely good for the dataset size.

Describe the image
This image is of a young woman eating a sandwich in a restaurant as she puts her hand up next to some kind of food. The sandwich appears to be made from small pieces
feeling optimistic about the results, i decided to scale up with a larger dataset, LLaVA-CC3M-Pretrain-595K, filtering the dataset for 0.3 similarity, which gave me about 100k images for the second training run:

What is the title of the book?
The book is titled ‘The Little Book of Algorithms for Deep Learning’
for test image 2:
What type of food is the girl holding?
The girl is holding a hamburger.
What color is the woman’s hair?
The woman’s hair is blonde.
What is the girl doing in the image?
The girl in the image is eating a hamburger with a large bite taken out of it .

What color is the train?
The train is red and white in color.
What is the bus doing in the image?
The bus in the image is traveling along a street with other cars and buses, using the dedicated bus lane on the right side of the road .
What kind of public transportation is in the image?
The public transportation in the image is a bus, specifically an articulated bus which has two sections connected by a hinge joint allowing it to bend and make turns easier. It is operating on transit lines .
training information and code
- len(train_set) = 133601
- len(test_set) = 14845
- batch_size = 8
- num_epochs = 2
- learning_rate = 1e-3
num_tokens = 8
hidden_dim = 4096
image_feature_size = 768
class ProjectionModule(nn.Module):
def __init__(self, input_dim, output_dim, sequence_length):
super(ProjectionModule, self).__init__()
self.linear1 = nn.Linear(input_dim, output_dim)
self.act = nn.ReLU()
self.linear2 = nn.Linear(output_dim, output_dim * sequence_length)
self.output_dim = output_dim
self.sequence_length = sequence_length
def forward(self, x):
x = self.linear1(x)
x = self.act(x)
x = self.linear2(x)
return x.view(-1, self.sequence_length, self.output_dim)
projection_module = ProjectionModule(image_feature_size, hidden_dim, num_tokens)
for epoch in range(num_epochs):
train_iterator = tqdm(
enumerate(train_loader), total=len(train_loader), desc=f"Epoch {epoch+1}"
)
for step, (image_features, inputs_embeds, labels, attention_mask) in train_iterator:
image_features = image_features.to(device)
inputs_embeds = inputs_embeds.to(device)
labels = labels.to(device)
attention_mask = attention_mask.to(device)
optimizer.zero_grad()
projected_embeds = projection_module(image_features)
first_tokens = labels[:, 0].unsqueeze(1)
padding = torch.full((labels.size(0), num_tokens), -100, dtype=torch.long).to(
device
)
rest_of_sequence = labels[:, delim_start_ids.size(1) :]
labels = torch.cat([first_tokens, padding, rest_of_sequence], dim=1)
first_embeds = inputs_embeds[:, : delim_start_ids.size(1) :]
remaining_embeds = inputs_embeds[:, delim_start_ids.size(1) : :]
inputs_embeds = torch.cat(
[first_embeds, projected_embeds, remaining_embeds], dim=1
)
num_ones_to_add = labels.size(1) - attention_mask.size(1)
ones_padding = torch.ones((attention_mask.size(0), num_ones_to_add), dtype=torch.long).to(device)
attention_mask = torch.cat([ones_padding, attention_mask], dim=1)
outputs = model(inputs_embeds=inputs_embeds.half(), labels=labels, attention_mask=attention_mask)
loss = outputs.loss
loss.backward()
optimizer.step()
eval_loss = evaluate(test_loader)
with labels being the caption tokens, properly padded and with BOS and pad tokens set to -100.
sadly, due to unfortunate rm -rfs, both models were lost, therefore i am unable to do proper evaluations on them.
second architecture
while the first architecture gave good results for its size, i knew that it would have severe limitations, such as understanding of text in images, due to starting from a very small input. therefore, for the second architecture, i decided to implement what i thought would be similar to AnyMAL, by taking the embedding of each patch of the image, to then generate 64 embeddings for the text models.
to do this i used a single linear layer that would take 9 ViT embeddings and generate one textual embedding. considering CLIP has 576 embeddings per image (after removing the [CLS] token), i would end up with the same amount of tokens as anyMAL.
however, during training, i noticed that after about 10k steps, the model had not dropped its loss, which was about 7, so i chose to end the training run. after attempting different sized models, the problem remained. this could mean two things, either the perceiver resampler was necessary to reach good results with visual modalities, or naively taking 9 embeddings to generate one for the LLM is not good enough, i have considered taking patches of 3 by 3 embeddings in order to preserve spacial data, but haven’t had the time to implement it.
third architecture
for the last architecture, i decided to implement several things from LLaVA and moondream, as i felt it would be the best way to get good results. similarly to the first LLaVA paper, i use a single layer that converts every ViT patch embedding to a textual one, and similarly to moondream, i chose to switch from CLIP to siglip-so400m-patch14-384. i kept the training objective from AnyMAL of predicting the caption after the model embeddings, as i was afraid that training using instructions would worsen the model’s reasoning capabilities.
in order to have a proper batch size, i implemented gradient accumulation, as due to the size of the prompts i could only have a batch size of one.
for this architecture, i chose to switch the model to Mistral-7B-Instruct-v0.2, as i felt there was a possibility that the fact Hermes was DPOd for instruct tuning could have played a role in the bad results of the second architecture.
i obtained these results:
for test image 1:
Describe the image
The little book on depth of learning is in the hands of a person, with the view of the sea.
What is the title of the book?
The little book of deep learning .
for test image2:
What type of food is the girl holding?
In “Elven woman” , a fictional world is in the game.
, the main character of the game, is a member of the Elven world .
The character is enjoying a meal at the local tavern with her friends and family.
The character is in a blue wig, wearing a white top and eating a burger, which are called " bun " in the game .
, - person, is a fictional character from a
What color is the woman’s hair?
The elf is the .
- : . - 68 ’s hair is white. What is the girl doing in the image? The girl is eating a hamburger
..
!!!, !!!... ————.
. -. -.
. -. -.
. ! .`
.
``` gif of the elf from the game "elves."
for test image 3:
What color is the train?
Red , a 350 foot tram of the modernist architecture
What is the bus doing in the image?
a bus is passing through the middle of traffic .
What kind of public transportation is in the image?
The red streetcar is a streetcar.
while there are visible improvements in textual understanding, it is very clear that the model was a lot worse, and was prone to generating a lot of garbage past its reply. to me this could be explained by lack of training data, the fact there is no EOS token in the caption prediction, and captions not being good enough.
to train a better model, i applied the following modifications:
- inspired by moondream, i added
<image></image>delimiters around the generated embeddings - every image was recaptioned with moondream2
- an EOS token was added at the end of each caption
you’ll notice that i didn’t add more training data, this was due to storage limitations (images and embeddings were taking 100s of gigabytes and i only have one terabyte), and it would show if the true bottleneck was training data or if the issues were related to my other intuitions.
i obtained these results:
for test image 1:
Describe the image
A person’s hand is shown holding a book in this image. The book is white, and the cover is white and yellow. Text is written on the top of the cover. The background includes a building with windows, doors, blinds, curtains, and a railing. The view outside includes trees, grass, and a fence.
A person’s hand is shown holding a book in this image. The book contains text and diagrams depicting various objects. The
What is the title of the book?
The title of the book is “Daily Motion and Thoughts”. The cover features a white background with a black background. A person’s hand is visible, holding the book.
The title of the book is “A Book on Distance Learning and Development” by V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V.V
for test image 2:
What type of food is the girl holding?
The image depicts a girl holding a sandwich in her hand, with the sandwich being brown and covered in cheese. A plate of food is placed on the table in front of her.
The girl is dressed in white and has green eyes. She is seated on a chair, which is surrounded by various other objects. The background is dark, and the scene appears to be indoors.
What color is the woman’s hair?
The woman in the image is depicted as holding a piece of bread in her hands. A plate with food is situated on a table, and a glass is placed on the table. The woman’s hair is white, and she appears to be wearing a gold ring. The background features a wall, a table, and various other unidentified objects.
The woman in this image is seated on a chair, with a plate of food (which may or may not contain cheese) in front.
What is the girl doing in the image?
The girl is depicted in the image, holding a sandwich and smiling. A table with plates, forks, knives, spoons, glasses, and a plate are present on the table.
The background is black, and the girl is wearing a white coat while holding a sandwich in her hands. The image appears to have been taken in a dimly lit room.
for test image 3:
What color is the train?
The tram’s interior, exterior, and front-on-boarding a building, the people on the sidewalk can be seen.
Both the train is red and white, and black and green. A few individuals are also present on the streets.
The buildings have windows, windows with curtains, and a pole and poles on the sides of these structures. The traffic signal lights are often located in the middle of a road, and a pedestrians’ line is
What is the bus doing in the image?
A bus is visible on the road, which is marked by a yellow and red octopole (a term for a person who walks on foot. The sky is also filled with clouds.
The image depicts a bridge and a rail bridge. The bridge’s design includes columns on both pillars, along with the use of stop signs.
Furthermore, the image shows people walking around the bus, along with various vehicles, trucks, bikes, cars, motor
What kind of public transportation is in the image?
The image shows a tram (vehicle) and a person standing on the sidewalk. A building with windows, doors, walls, etc. The tram is in motion on the tracks, while a few people walk by the tram.
Some vehicles are also present on the road, along with traffic signals. The sky features a boarding station, traffic lights, traffic signals, and pedestrians walking around.
The building’s exterior is visible from the tram’s rear window..
while the model was less prone to generating garbage tokens after its response, the results were still very bad, which is most likely due to lack of training data.
finally, i trained a model by using LLaVA’s instruct style training, my intuition was correct and the model generated a caption no matter the question.
training information and code
- len(train_set) = 133601
- len(test_set) = 14845
- batch_size = 1
- accumulation_steps=16
- num_epochs = 1
- learning_rate = 1e-3
- lr scheduler = cosine decay with 0.003 len(train_set) warmup steps
hidden_dim = 4096
image_feature_size = 1152
class ProjectionModule(nn.Module):
def __init__(self, image_feature_size, hidden_dim):
super(ProjectionModule, self).__init__()
self.mlp = nn.Sequential(nn.Linear(image_feature_size, hidden_dim))
def forward(self, x):
n, _, _ = x.size()
x = x.view(n * num_tokens, image_feature_size)
x = self.mlp(x)
x = x.view(n, num_tokens, hidden_dim)
return x
projection_module = ProjectionModule(image_feature_size, hidden_dim)
for epoch in range(num_epochs):
train_iterator = tqdm(
enumerate(train_loader), total=len(train_loader), desc=f"Epoch {epoch+1}"
)
optimizer.zero_grad()
accumulated_loss = 0.0
for step, (image_features, inputs_embeds, labels, attention_mask) in train_iterator:
image_features = image_features.to(device)
inputs_embeds = inputs_embeds.to(device)
labels = labels.to(device)
attention_mask = attention_mask.to(device)
projected_embeds = projection_module(image_features)
first_tokens = labels[:, : delim_start_ids.size(1)]
padding = torch.full((labels.size(0), num_tokens), -100, dtype=torch.long).to(
device
)
rest_of_sequence = labels[:, delim_start_ids.size(1) :]
labels = torch.cat([first_tokens, padding, rest_of_sequence], dim=1)
first_embeds = inputs_embeds[:, : delim_start_ids.size(1) :]
remaining_embeds = inputs_embeds[:, delim_start_ids.size(1) : :]
inputs_embeds = torch.cat(
[first_embeds, projected_embeds, remaining_embeds], dim=1
)
num_ones_to_add = labels.size(1) - attention_mask.size(1)
ones_padding = torch.ones((attention_mask.size(0), num_ones_to_add), dtype=torch.long).to(device)
attention_mask = torch.cat([ones_padding, attention_mask], dim=1)
outputs = model(inputs_embeds=inputs_embeds.half(), labels=labels, attention_mask=attention_mask)
loss = outputs.loss
loss = loss / accumulation_steps
loss.backward()
accumulated_loss += loss.item()
if (step + 1) % accumulation_steps == 0 or step + 1 == len(train_loader):
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
accumulated_loss = 0.0
epoch_progress = (step + 1) / len(train_loader)
eval_loss = evaluate(test_loader)
final model
after reaching the month mark, i decided to retrain using the first architecture (dubbed doubutsu-smol) in order to showcase a working model, i kept the original captions in the dataset since they seemed better for textual understanding, but added the image delimiters, and used cosine decay. i also increased the dataset size since the single CLIP embedding wouldn’t take too much space and increased the generated embeddings to 16 instead of 8, which gave me the following results:
for test image 1:
Describe the image
The image is a book lying on top of a blue, white and yellow notebook with the title’s description of the book’introduction to machine learning ‘on the cover . The book rests on top of a wooden table with a small plant in the background.
What is the title of the book?
the title of the book is
a short introduction to programming
for test image 2:
What type of food is the girl holding?
the girl is holding a piece of food that looks like a sandwich or a bun with cheese in it.
What color is the woman’s hair?
the woman in the image has blonde hair .
What is the girl doing in the image?
the girl in the image is eating a sandwich while sitting on a chair and looking at something on her phone screen
for test image 3:
What color is the train?
the streetcar is red in color.
What is the bus doing in the image?
the image shows a red and white bus traveling on a street
What kind of public transportation is in the image?
the image shows a city bus in motion
while these current results are better than other architectures, they are still worse than the very first model, which is disappointing. it might be worth it to do another training run replicating the exact parameters as the best smol model.
what i learnt
- i need to be more rigorous with my work: i was very sloppy multiple times during this project, i deleted important files, i didn’t set up a git repository, i tried things out without properly documenting the results of the changes. while this is is a fine approach when doing basic projects, this just doesn’t fly while doing research. i will be a lot more careful from now on. i also should have set up more evaluations, all of this was done on vibes and i felt that until i had the right model i didn’t need to worry about it, but i didn’t get it and now lost valuable informations on my results
- i need to buy a lot more storage: rather self evident in this case
- it’s okay if things go bad: i entered a research field full of people that are way smarter than me, working in teams, and working on the subject for a long time. everything i attempted was most likely tried by another group of people that found it didn’t work, so i shouldn’t expect to have amazing results unless i perfectly replicated known methods.
- i shouldn’t base my worth on my results: during this project, i had a habit of feeling like i was worthless because i didn’t reach SOTA, which is delusional. research is difficult and things often go wrong; it’s okay to fail.
what now?
i’m not sure currently, i released the last smol model here so that you can try it, but obviously don’t expect good results. if i am not too burnt out, i will retrain smol to be as close as possible to the best model, i also want to try throwing more data at the LLaVA-like architecture, as i feel it is the one with most potential.
conclusion
all in all, it was an interesting experience to say the least. i can’t say i’m proud of my results, but i’m happy i tried something new, i learnt a lot and hope i can share something great soon, since it would allow adding any modality to models for very cheap, while also not modifying the base model.